En esta clase
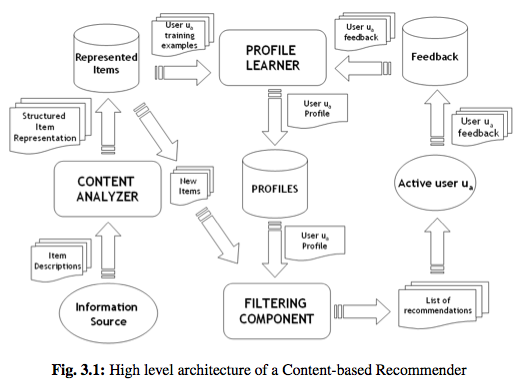
- Contenido en lugar de ratings
- Representación de Espacio Vectorial
- TF-IDF
- Buscando Items Similares
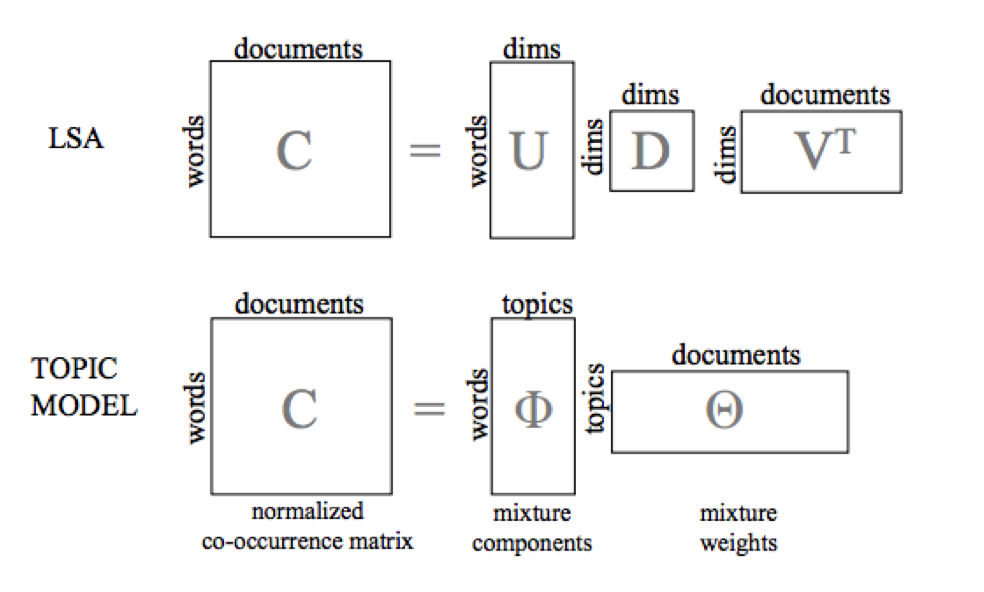
- Representación en Espacio Latente
Denis Parra
Profesor Asistente, DCC, PUC CHile
PROS
CONS
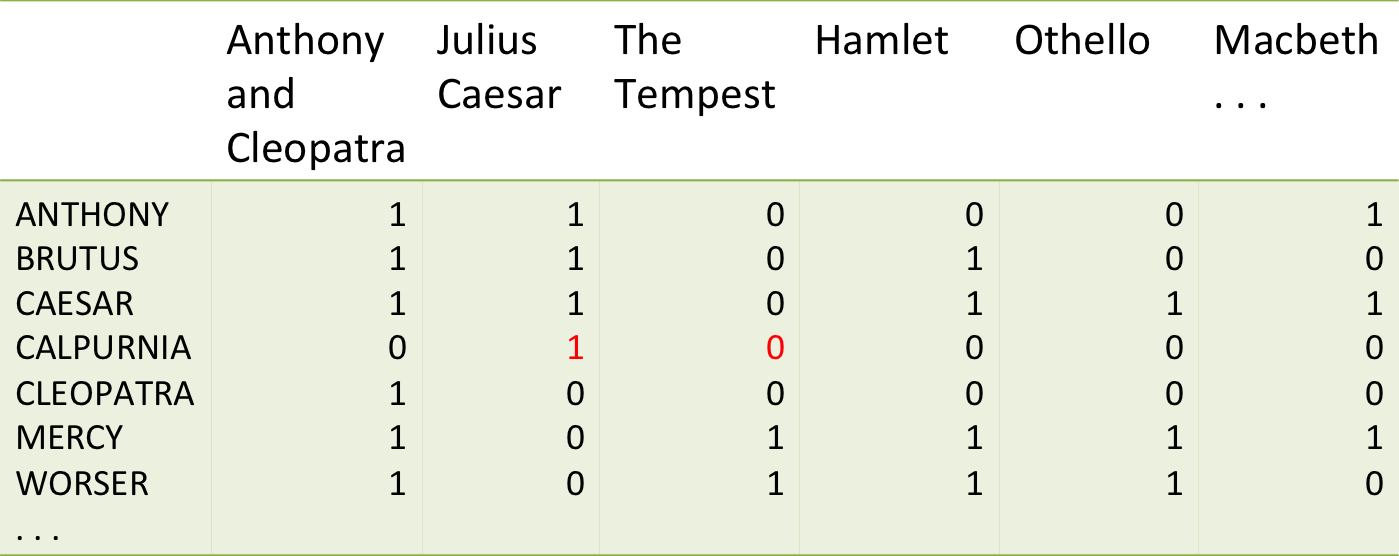
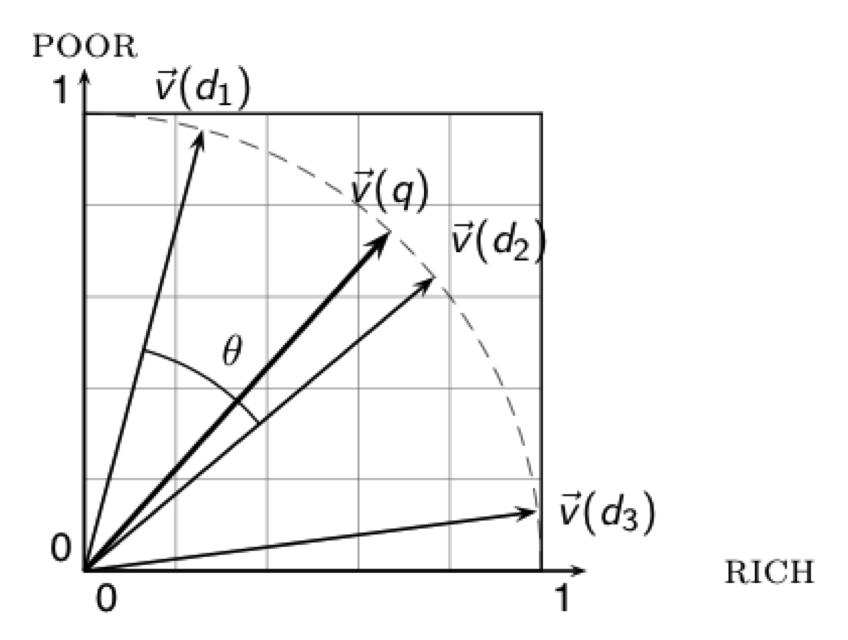
Cada documento se representa como un vector, el "peso" de cada palabra para ese documento puede darse en base a la frecuencia del término en el documento.
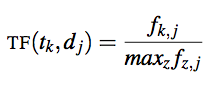
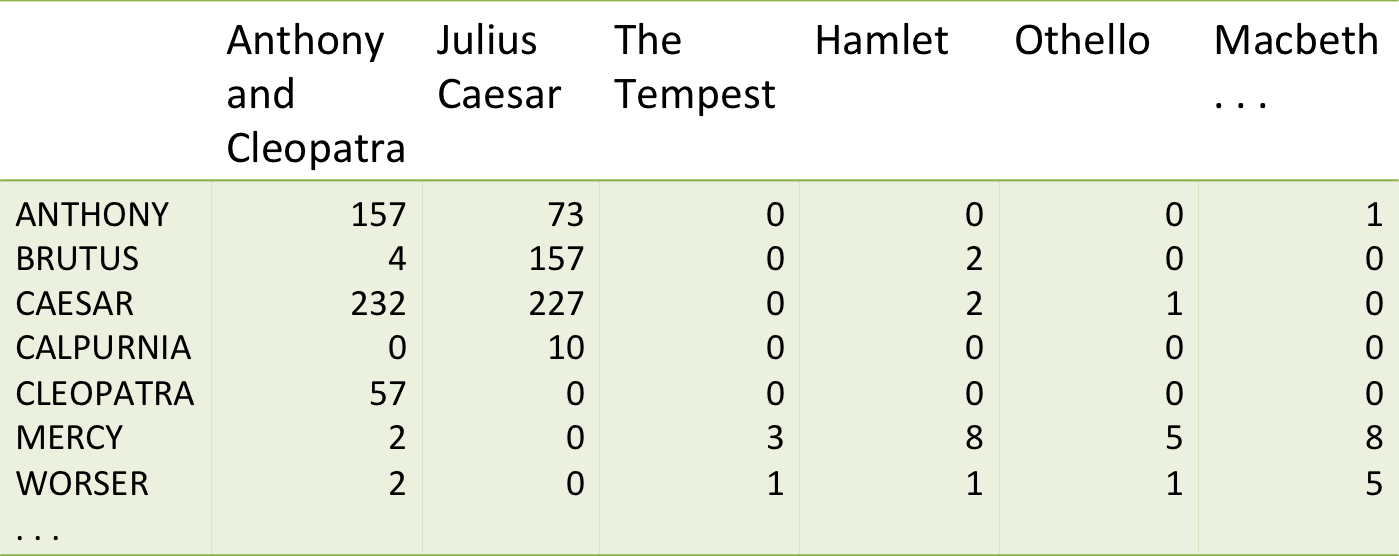
Podemos normalizar el valor en función de la frecuencia máxima de cualquier término en el documento.
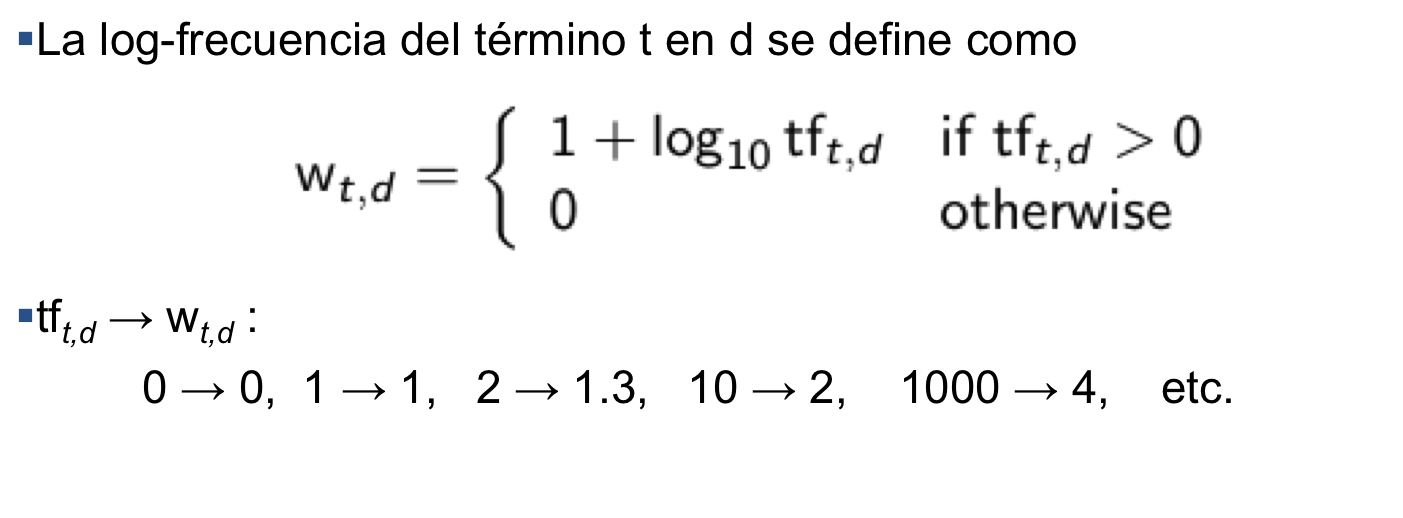
Pero el hecho que un término \(x\) aparece 100 veces y otro término \(y\) sólo 10 veces, no hace a x 10 veces más relevantes; por lo tanto podemos usar un logaritmo.
Bajo la intuición de que un término que aparece en sólo unos poco documentos podría ser descriptivo, podemos considerar la "Inverse Document Frequency" y combinarla con la "Term Frequency":
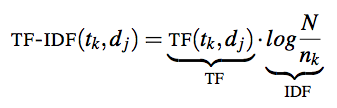
Done \(t_k\) es el término \(k\), \(d_j\) es el documento \(j\).

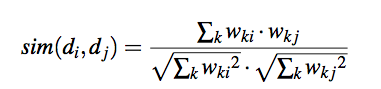
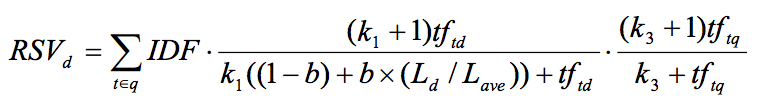
Ref: Denis Parra and Peter Brusilovsky. 2009. Collaborative filtering for social tagging systems: an experiment with CiteULike. In Proceedings of the third ACM conference on Recommender systems (RecSys '09) http://doi.acm.org/10.1145/1639714.1639757
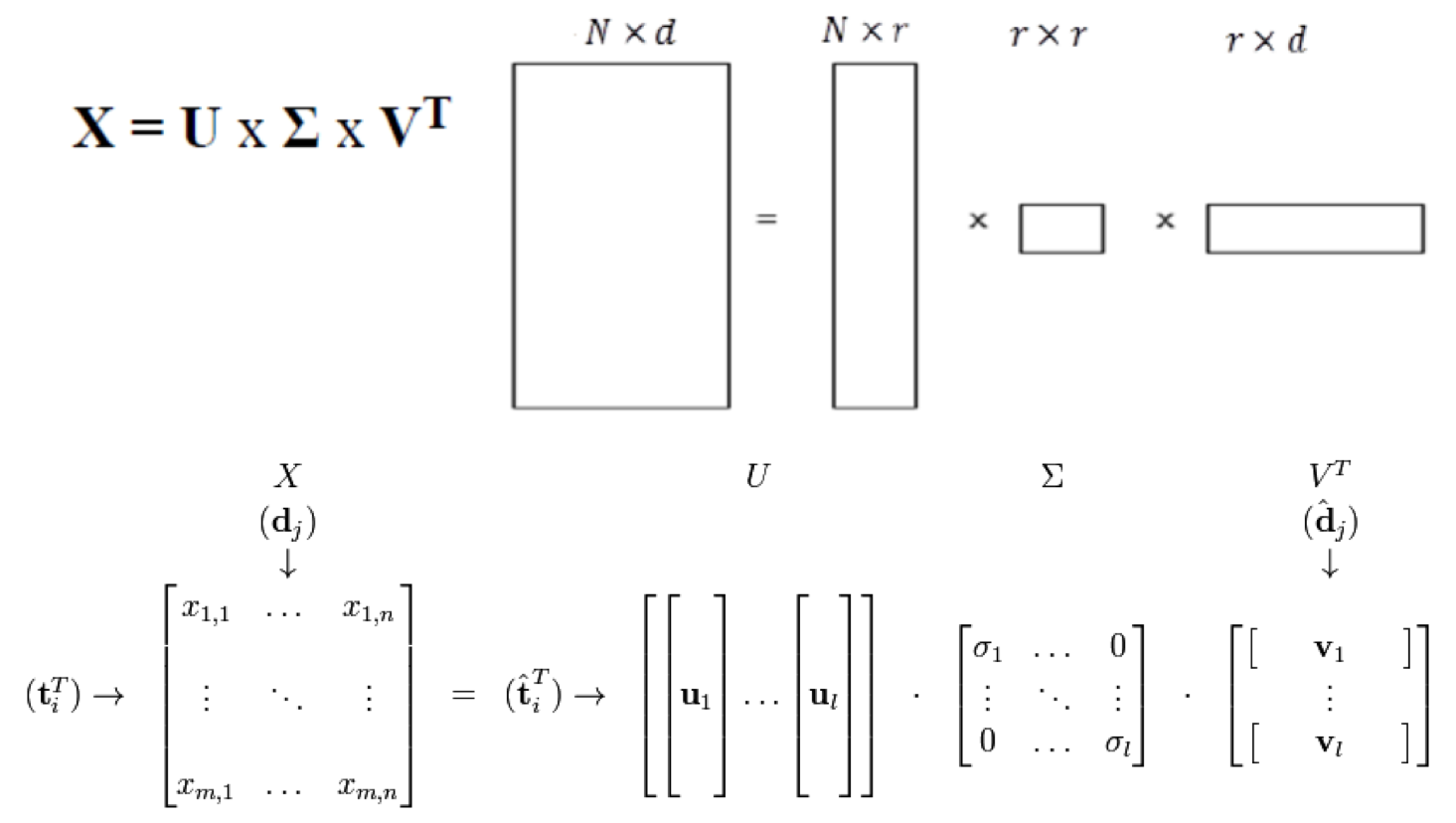
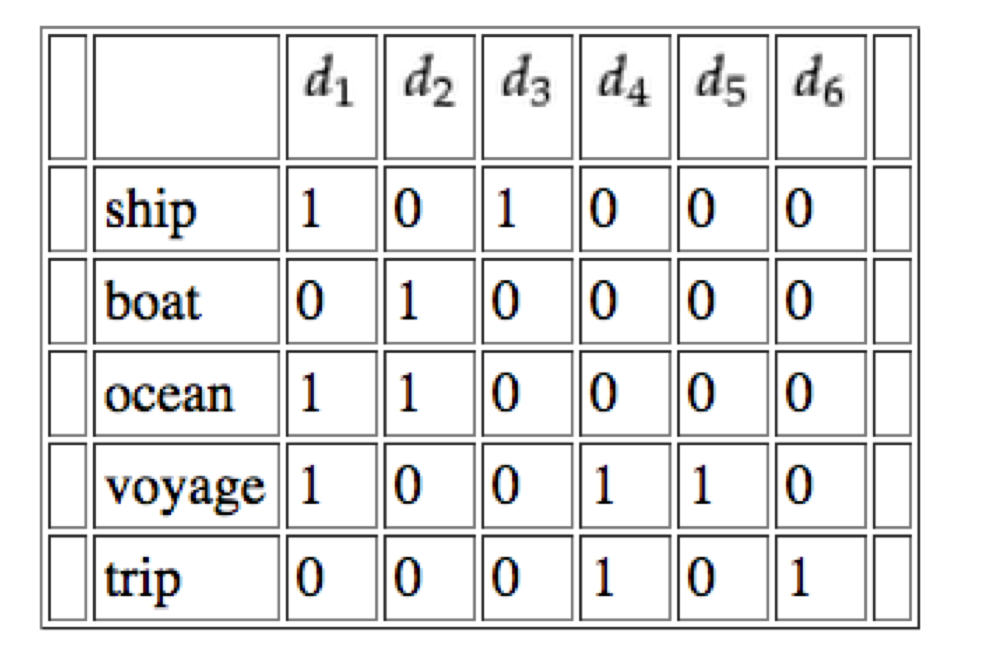
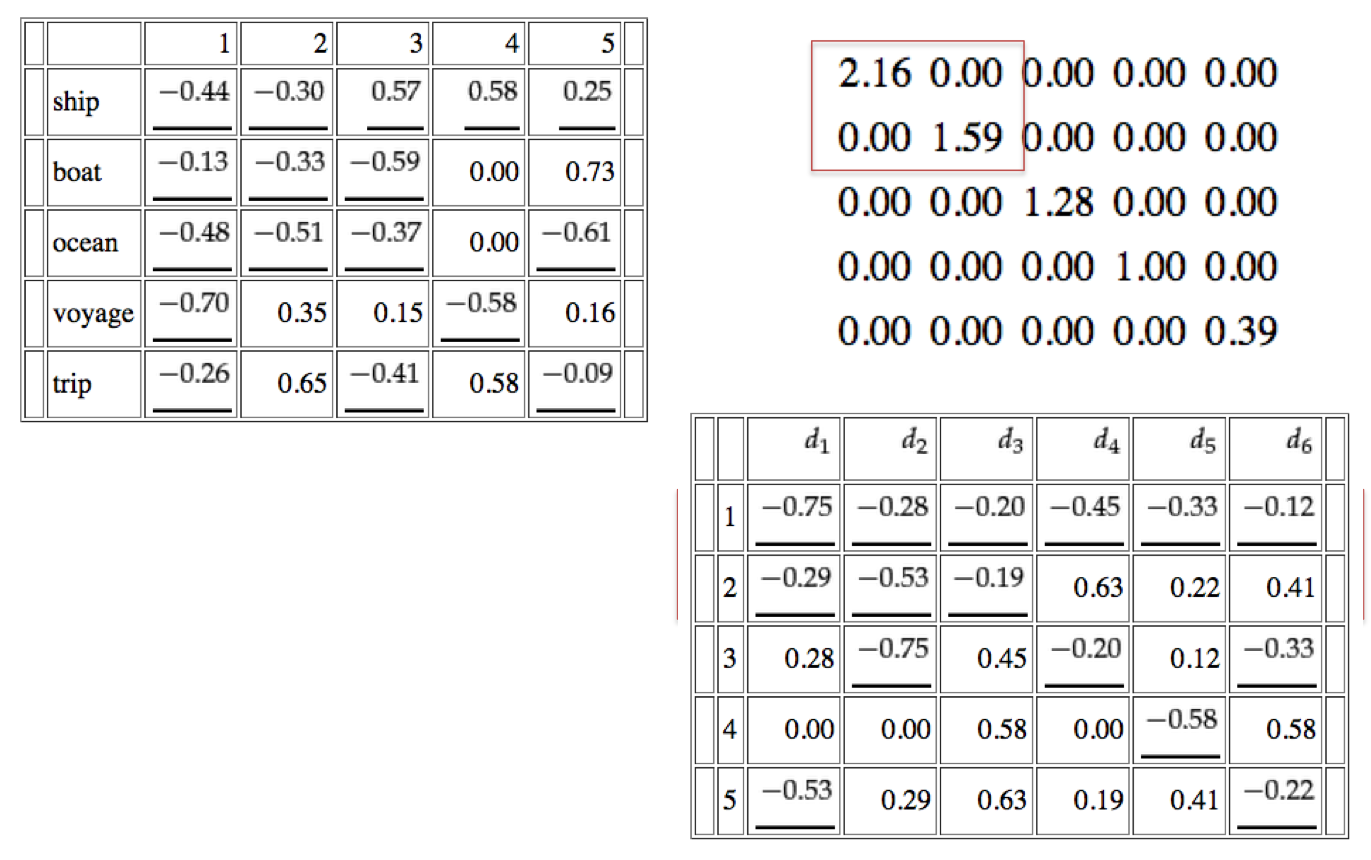

Demo: http://dfao-uc.github.io/

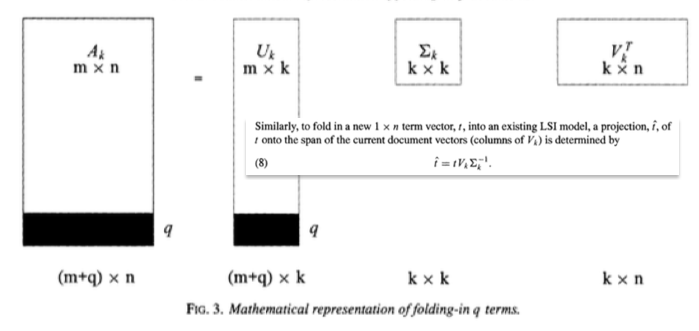


Manning, C. D., Raghavan, P., & Schütze, H. (2008). Introduction to information retrieval (Vol. 1, p. 6). Cambridge: Cambridge university press.
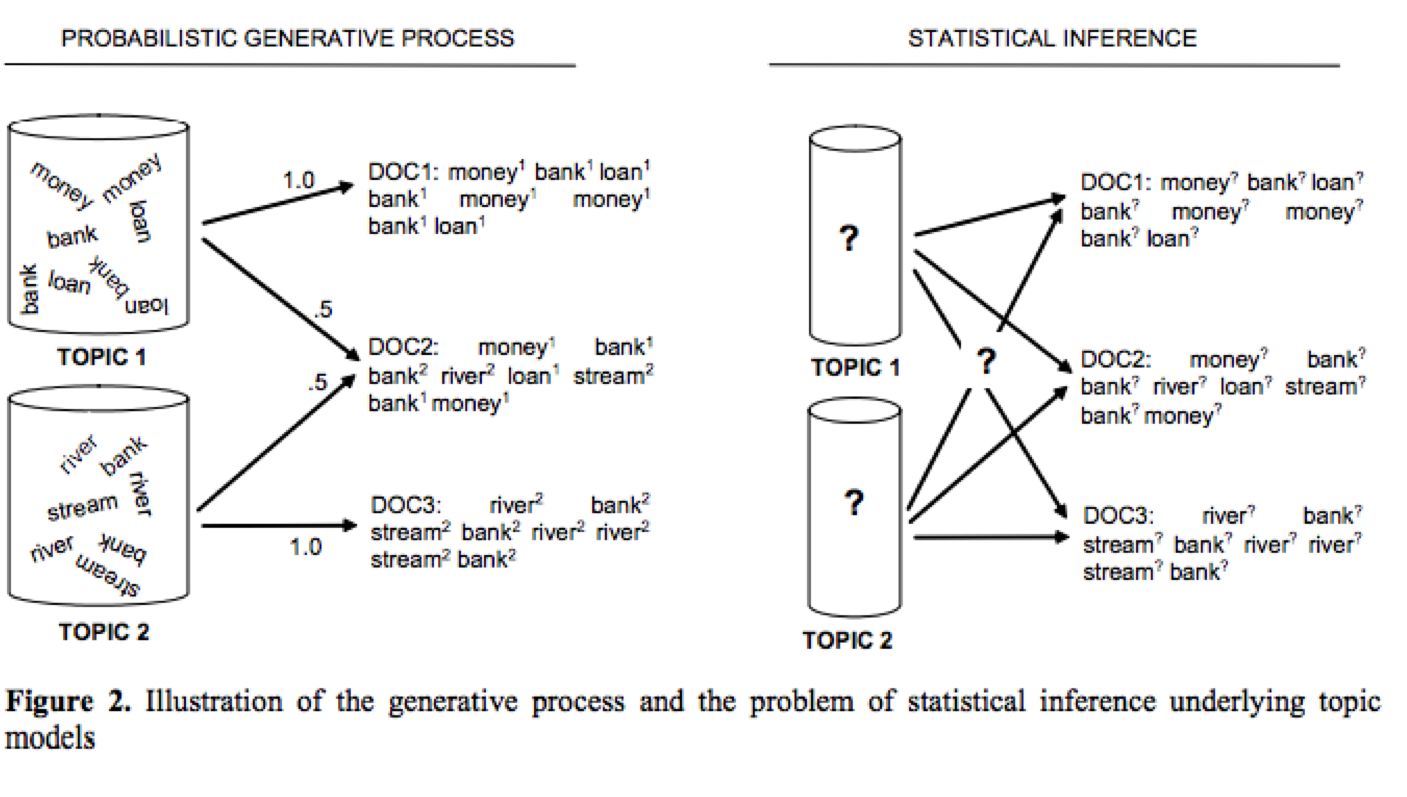
Steyvers, M., & Griffiths, T. (2007). Probabilistic topic models. Handbook of latent semantic analysis, 427(7), 424-440.
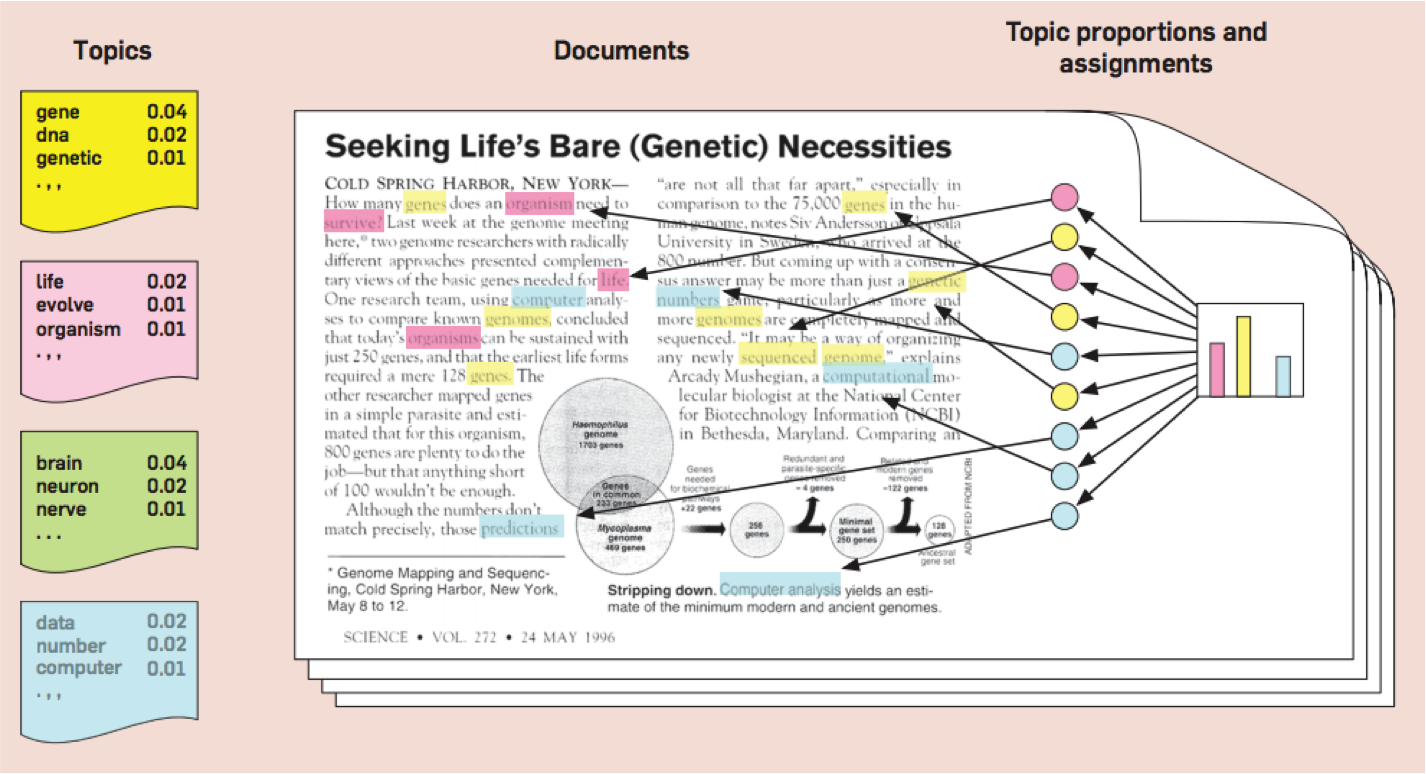
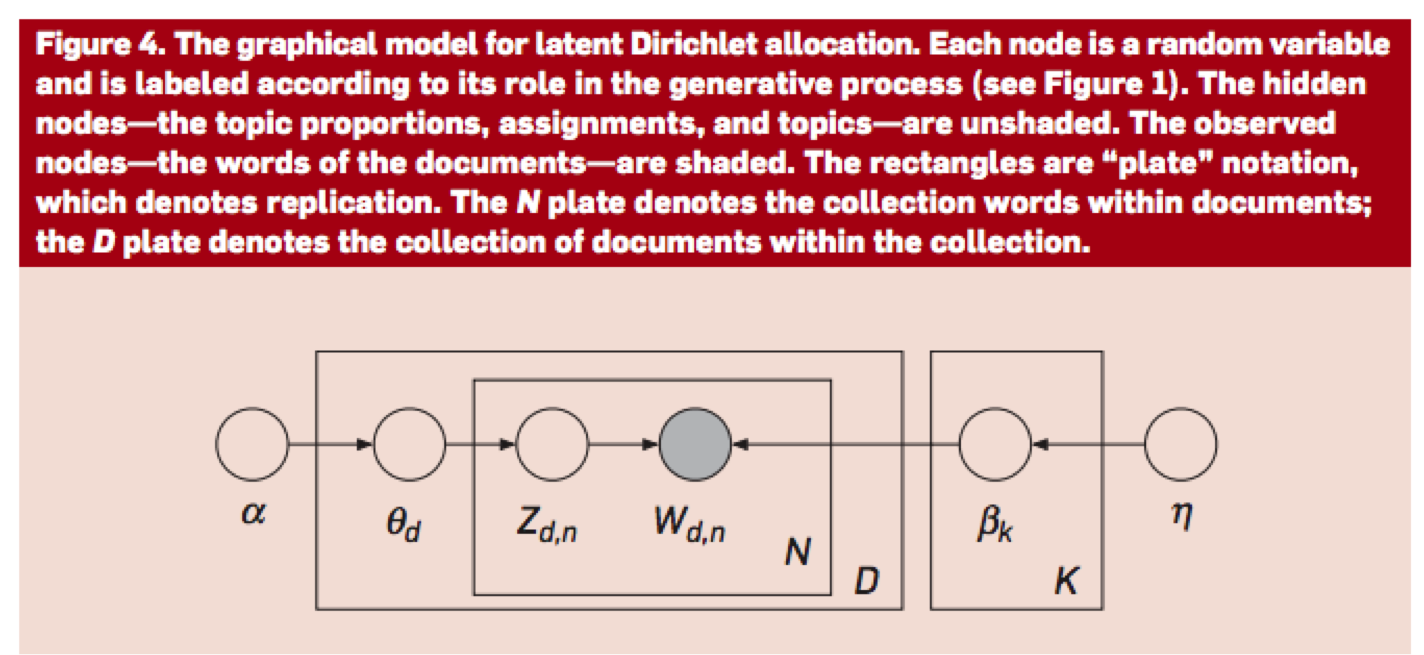
Blei, D. M. (2012). Probabilistic topic models. Communications of the ACM, 55(4), 77-84.