En esta clase
- Actividades principales del semestre: Blog, Tarea 1, Presentacion, Proyecto Final
- Definición y un poco de Historia
- Ranking No Personalizado
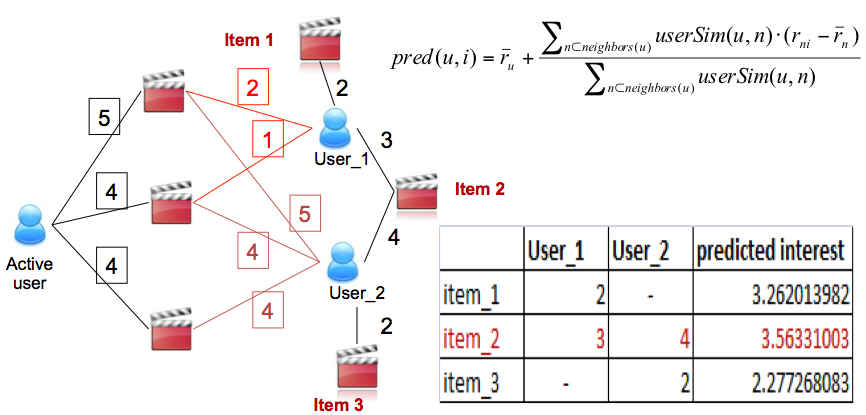
- User-Based Collaborative Filtering
- Referencias
Denis Parra, Profesor Asistente, DCC PUC Chile
Ayudantes: Manuel Cartagena y Antonio Ossa
Recommender Systems aim to help a user or a group of users in a system
to select items from a crowded item or information space.
(MacNee et. al 2006)
R. Burke tenía su propia definición, similar a esta, pero agregaba ...in a personalized way.


\[\forall c \in C, s^{\prime}_{c} = \arg\!\max_{s \in S} u(c,s)\] \[u:C \times S \to R,\ funcion\ de\ utilidad\] \[R:\ conjunto\ recomendado\ de\ items\\ C:\ conjunto\ de\ usuarios\\ S:\ conjunto\ de\ items\]

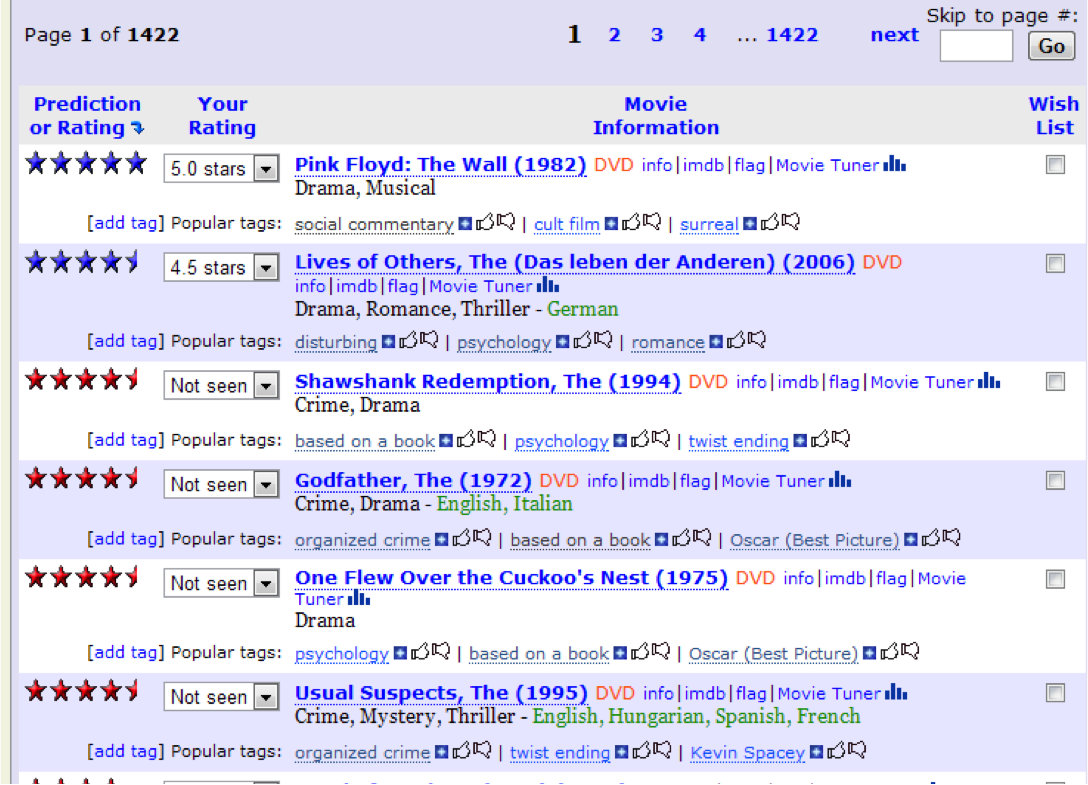
Recomendaciones estilo Amazon.com

Link to PDF file
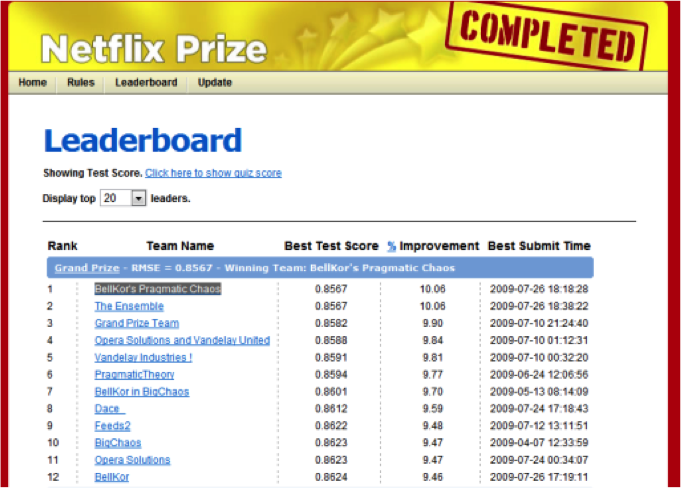
Link to Amatriain 2012


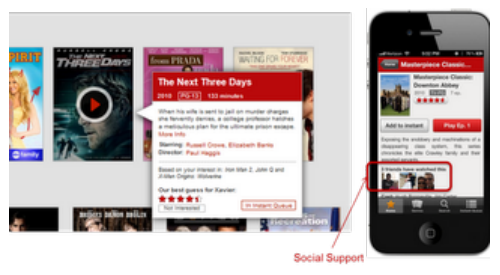
Link to Amatriain 2012
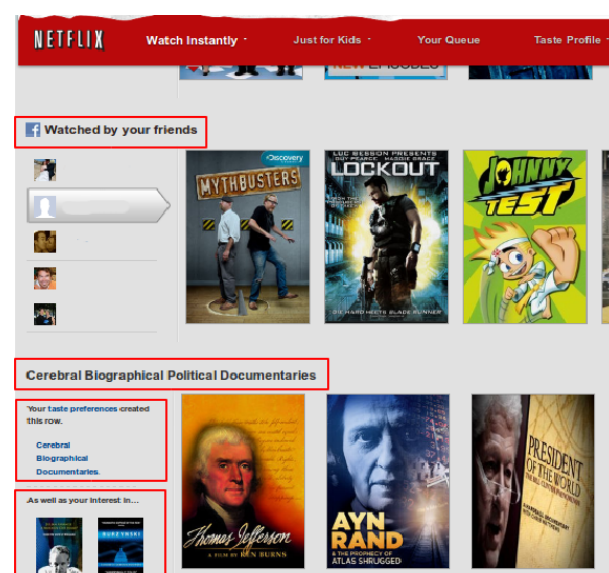
Link to Amatriain 2012
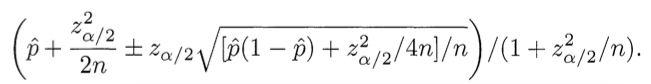
Donde \(\hat{p}\) es la proporción (estimada) de ratings positivos, \(z_{\alpha/2}\) es el \((1-\alpha/2)\) cuantil de la distribución normal, y \(n\) el número de ratings. \(\alpha\), también llamado nivel de significancia estadístico, generalmente se considera 95%.
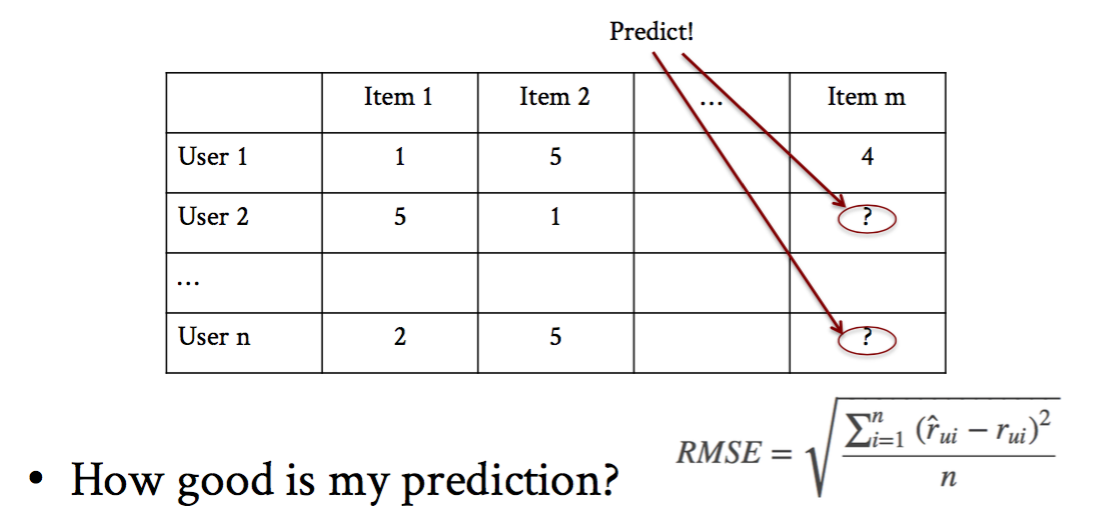
Dos tareas son necesarias:
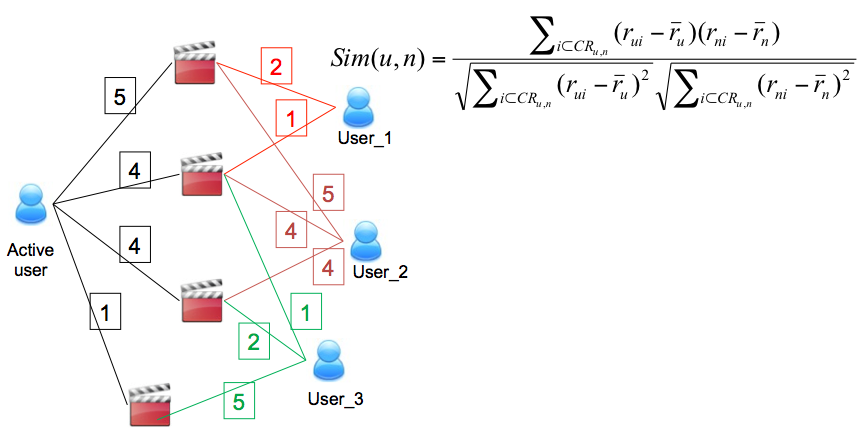
SOLUCION
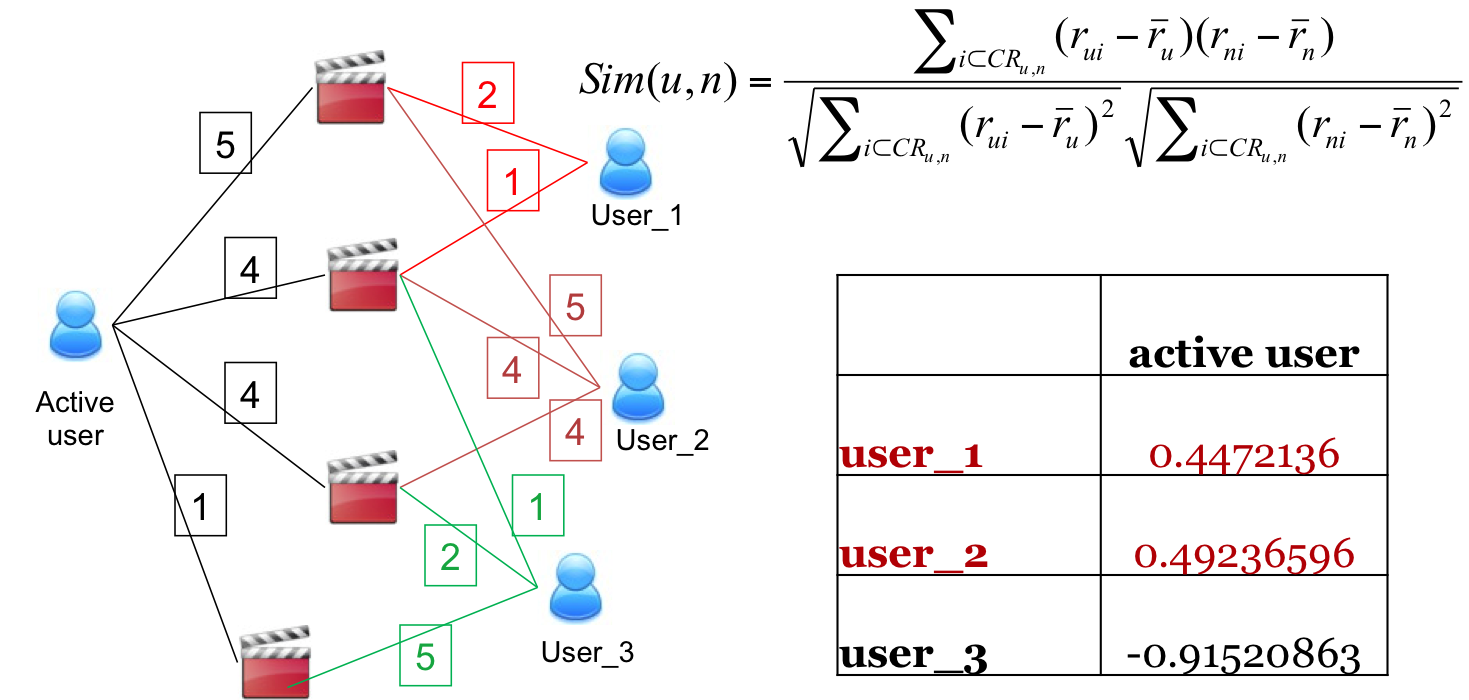
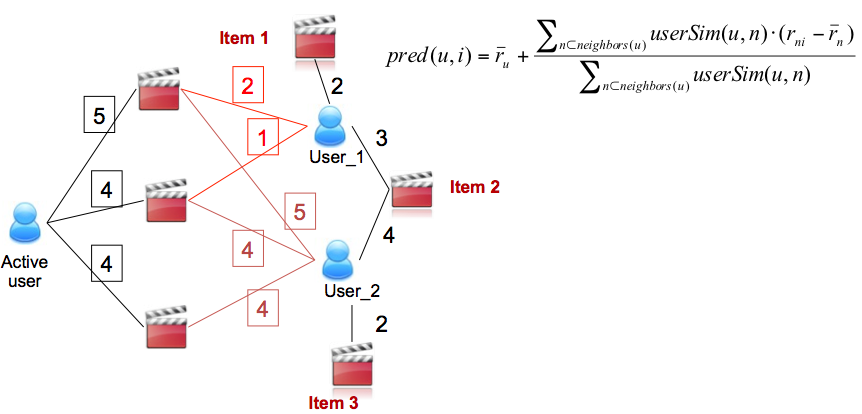
SOLUCION