Tarea 1: Deadline nuevo, Jueves 8 de Septiembre.
Lecturas en el semestre: Ya fueron actualizadas en el sitio web del curso.
Denis Parra
Profesor Asistente, DCC, PUC CHile
Tarea 1: Deadline nuevo, Jueves 8 de Septiembre.
Lecturas en el semestre: Ya fueron actualizadas en el sitio web del curso.
El trabajo ganador del Netflix Prize se basa en una composición (blending) de varios modelos, pero la técnica de factorización matricial es la más importante junto con Restricted Boltzmann Machines; de hecho, fueron las únicas 2 que Netflix puson realmente en producción terminado el concurso.
De ahí en adelante, una gran parte de los trabajos en sistemas recomendadores se fundan en estos modelos factorización matricial, también llamados de factores latentes.
\[ r_{ui} = q_{i}^T \cdot p_u\]

¿Cómo encontrar los valores de los vectores \(q_i\) y \(p_u\)?
Opción 2: Usar la siguiente función de pérdida, como un problema de optimización con regularización \(l_2\) que podemos resolver con stochastic gradient descent u otras técnicas.
\[ \min_{q*,p*} \sum_{(u,i) \in K} (r_{ui} - q_{i}^T \cdot p_u)^2 + \lambda(||q_i||^2 + ||p_u||^2)\]
donde \(K\) es el conjunto de pares \((u,i)\) para los cuales \(r_{ui}\) es conocido (training set).
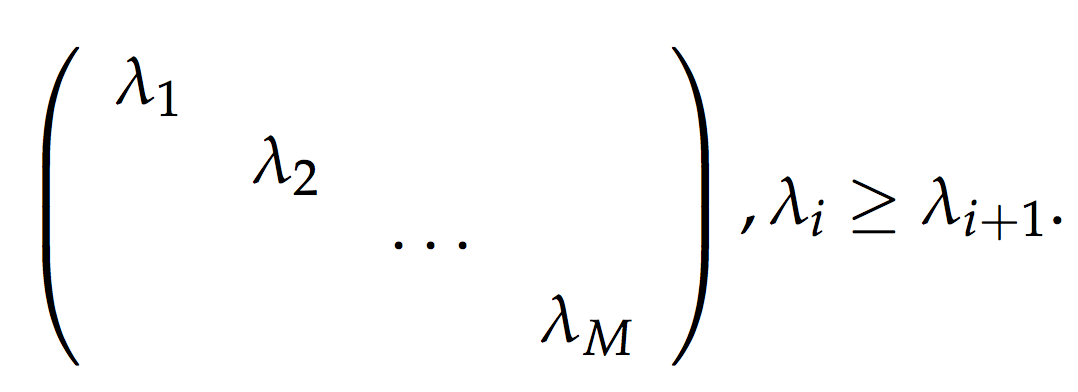
ref: Introduction to Information Retrieval, Manning et. al (2010)
Teorema de diagonalización simétrica: Sea \(A\) una matriz \(m \times m\) cuadrada y simétrica con valores reales, con \(m\) vectores propios linealmente independientes. Luego, existe una descomposición \[A = QSQ^{T},\] donde las columnas de \(Q\) son los vectores propios ortogonales y normalizados de \(A\), y \(S\) es una matriz diagonal cuyas entradas son los valores propios de \(A\). Más aún, todas las entradas de Q son reales y tenemos que \(Q^{-1}=Q^{T}\).
ref: Introduction to Information Retrieval, Manning et. al (2010)
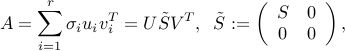
donde \(U \in \Bbb{R}^{m \times m}\) y \(V \in \Bbb{R}^{n \times n}\) son ambas matrices ortogonales, y la matriz {S} es diagonal:
\[S = diag = (\sigma_1 , \ldots, \sigma_r),\]
donde los números positivos \(\sigma_1 \ge \ldots \ge \sigma_r >0\) son únicos, y son llamados los valores singulares de \(A\). El número \(r \ge min(m,n)\) es igual al ranking de \(A\) y la tripleta \((U,\tilde{ {S}},V)\) es llamada la singular value decomposition (SVD) de \(A\).
Las primeras \(r\) columnas de \(U:u_i,i=1,\ldots,r\) (respectivamente \(V:v_i,i=1,\ldots,r\) ) son llamados los vectores izquierdos (resp. derechos) singulares de \(A\), y satisfacen:
\[Av_i = \sigma_i u_i, \;\; u_i^T A = \sigma_i v_i, \;\; i=1,\ldots,r.\]
ref: https://inst.eecs.berkeley.edu/~ee127a/book/login/thm_svd.html
Las matrices que usualmente usamos de usuario-item no son cuadradas ni simétricas.
Pero si consideramos el teorema SVD
\[A = U\tilde{ {S}}V^T\]
y luego que \(AA^T\) es una matriz cuadrada y simétrica, tenemos:
\[AA^T = U\tilde{ {S}}V^T \; V\tilde{ {S}}U^T = U\tilde{ {S}}^2U^T\]
y de forma análoga
\[A^TA = V\tilde{ {S}}U^T \; U\tilde{ {S}}V^T = V\tilde{ {S}}^2V^T\]
podemos calcular las matrices \(U\), \(V\) y \(\tilde{ {S}}\).
ref: Introduction to Information Retrieval, Manning et. al (2010)
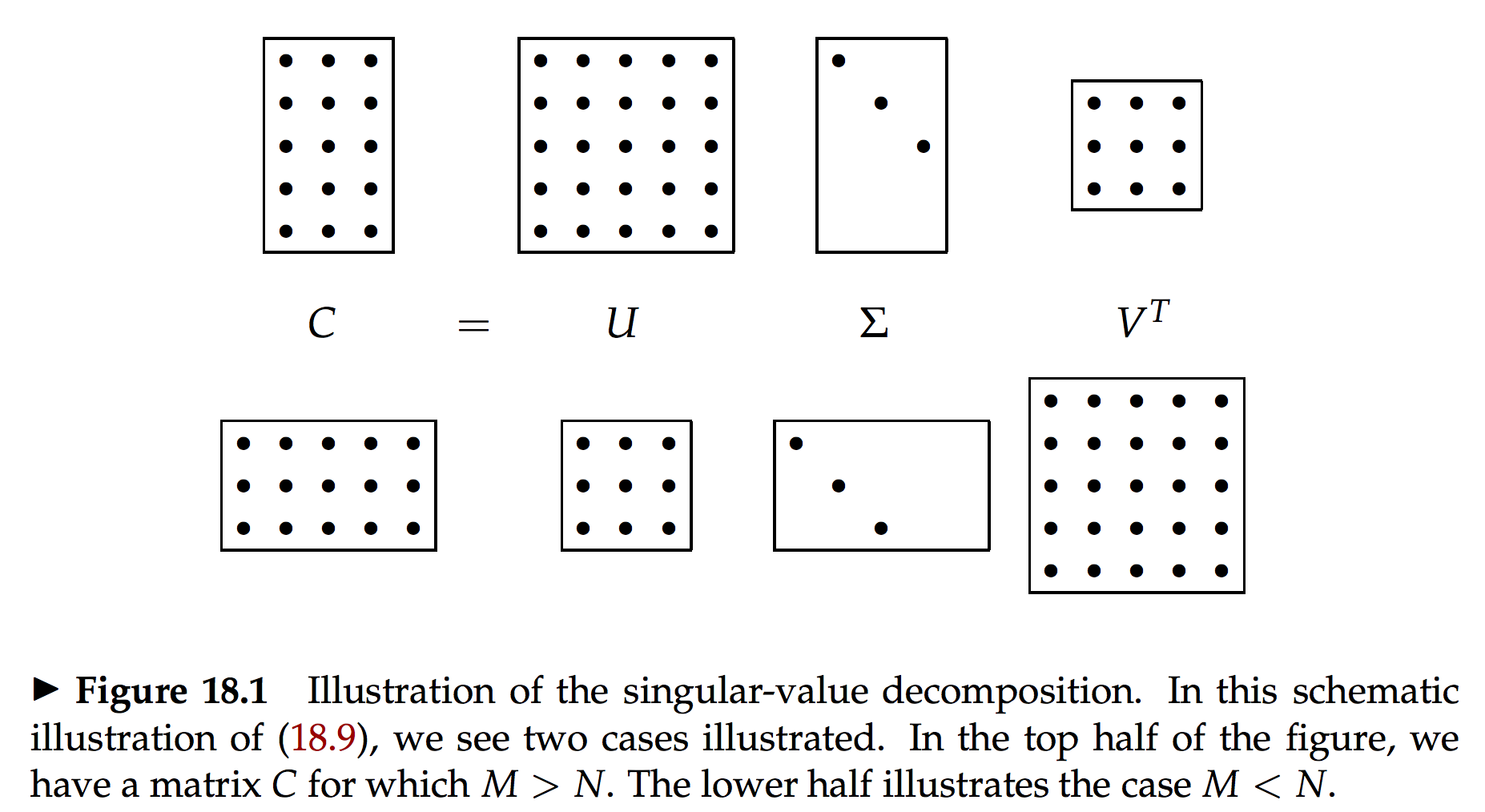
ref: Introduction to Information Retrieval, Manning et. al (2010)
\[||X||_F = \sqrt{\sum_{i=1}^{M}\sum_{j=1}^{n}X_{ij}^2}\]


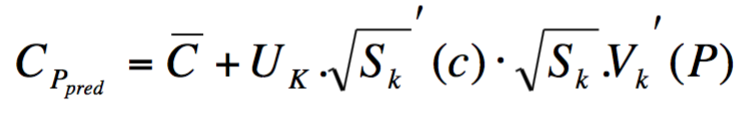
Una desventaja importante es cómo calcular la representación latente para nuevos usuarios.
ref: Sarwar et al (2000). Application of Dimensionality Reduction in Recommender System -- A Case Study.
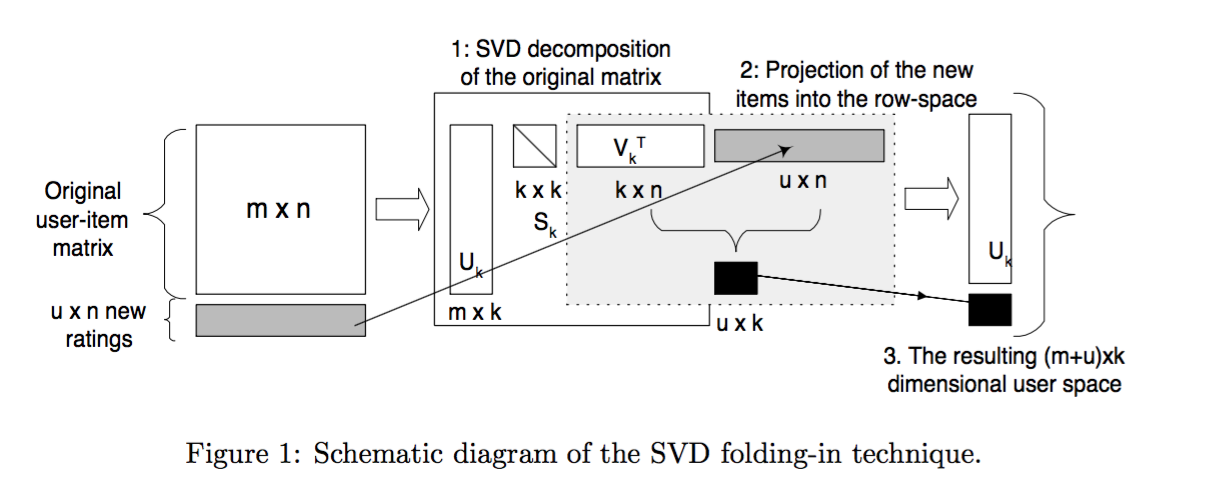
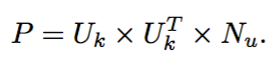

Calcular la SVD de una matriz es muy costoso, \(O(m^2n)\)
Problemas debido a la gran cantidad de celdas vacías en la matriz usuario-ítem obligaron a los autores en (Sarwar, 2000) a pre-llenarla.
El modelo tradicional de SVD no está definido cuando hay un conocimiento parcial de la matriz.
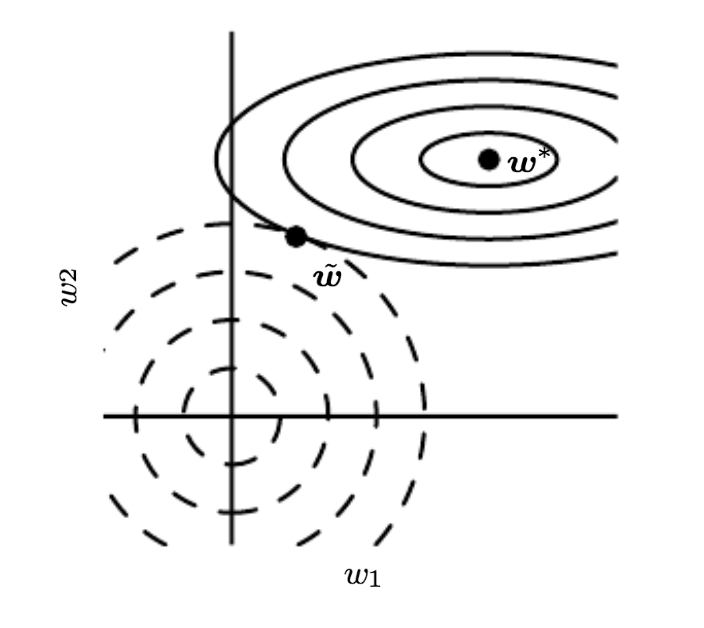
Utilizar un método convencional también corre el peligro de over-fitting.
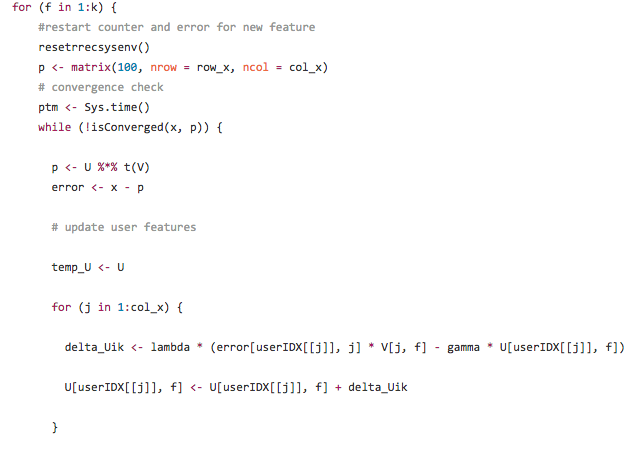
Basada en Stochastic Gradient Descent, considerando trabajo de Gorrell (2005)
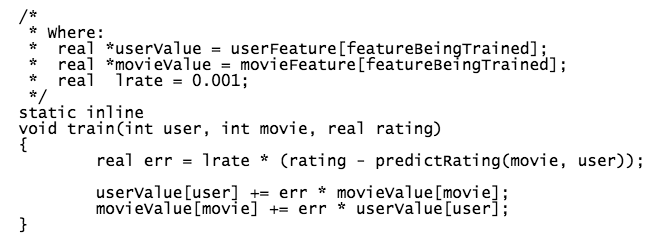
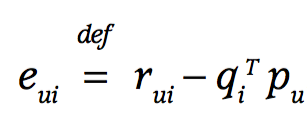
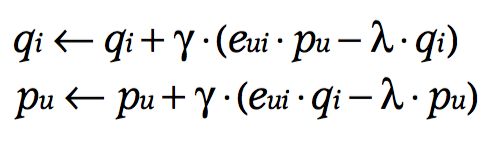
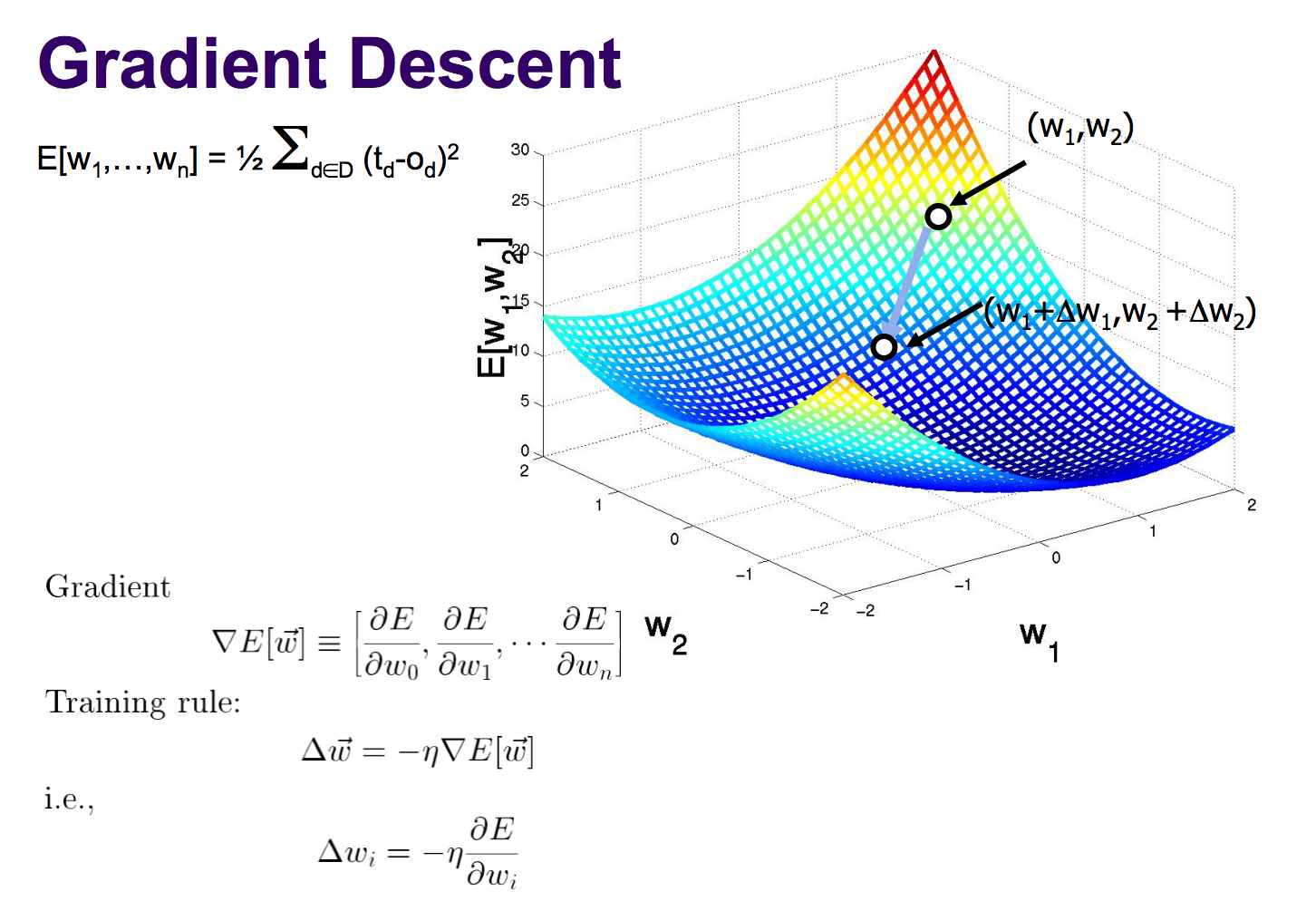

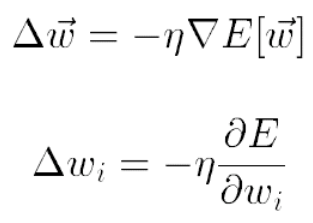
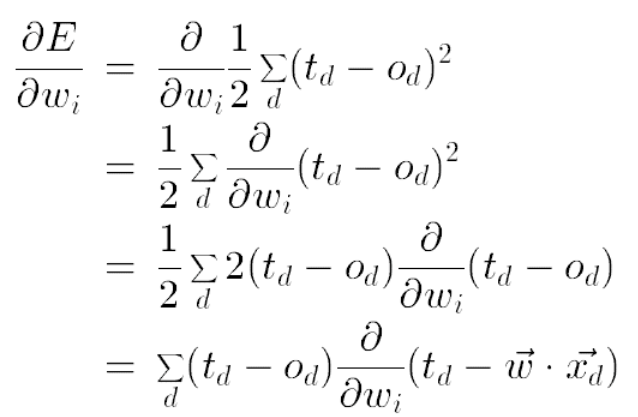
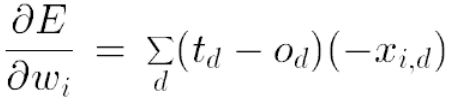

Al tener tan pocos datos la matriz (densidad del 1%-2%), el procedimiento corre el riesgo de sobre-entrenarse (over-fitting). Un regularizador permite penalizar valores muy altos de los coeficientes de los vectores latentes (Bishop, 2007;Goodfellow et al, 2016)
|

|
Por eso se agregan los términos \(||p_u||\) y \(||q_i||\) a la función de pérdida (loss function) \[\min_{q*,p*} \sum_{(u,i) \in K} (r_{ui} - q_{i}^T \cdot p_u)^2 + \lambda(||q_i||^2 + ||p_u||^2) \]
De esa forma, las reglas de actualización del SGD incluyen (siendo \(\gamma\) el learning rate):

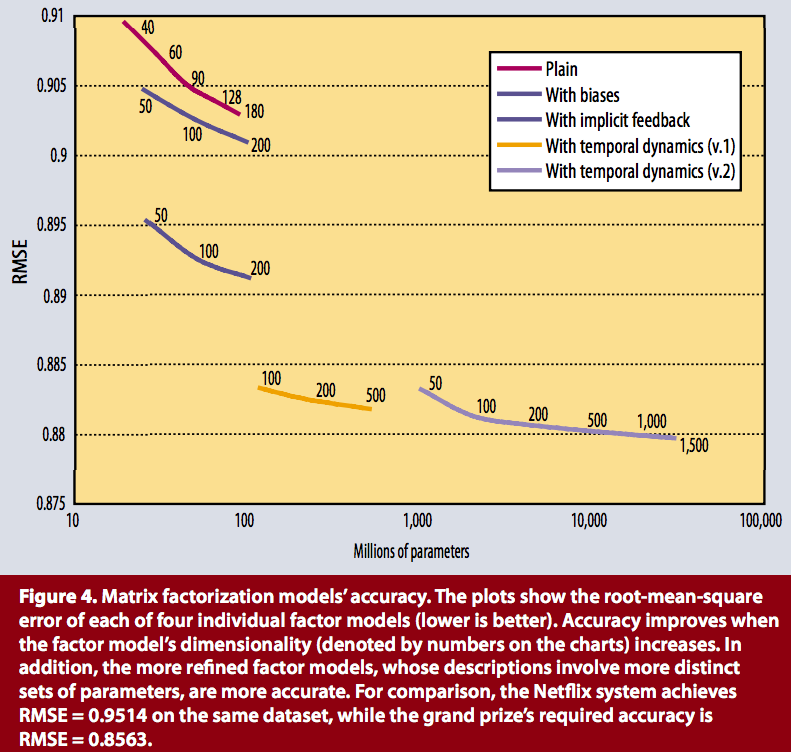
El modelo de Koren et al. para el Netflix prize incorpora los biases de usuarios e items:
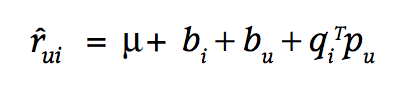
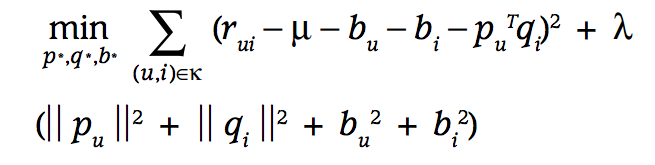
Luego de incluye información implícita en el modelo incorporando \(N(u)\)
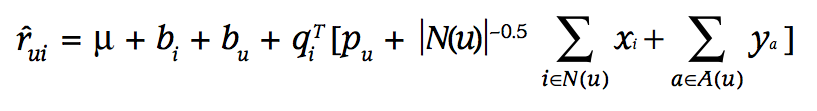
Luego de incluye información temporal (concept drift)
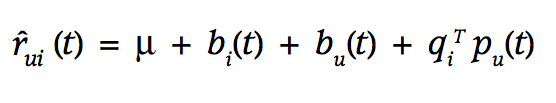
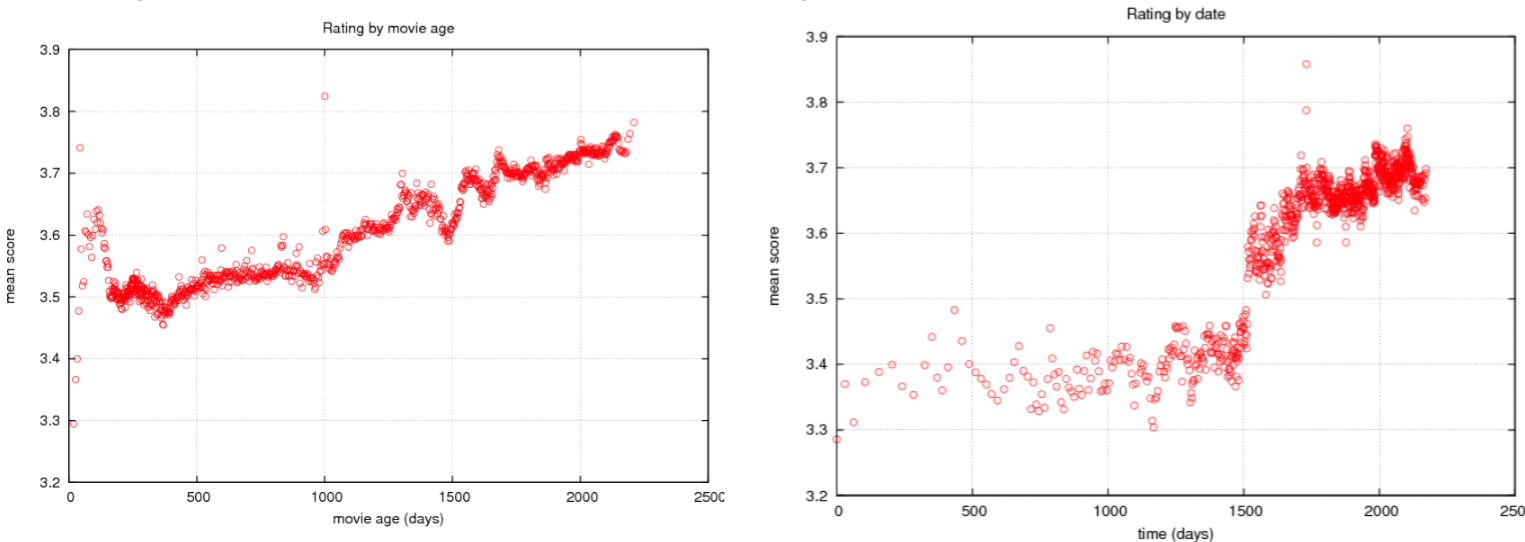
Collaborative Filtering for Implicit Feedback Datasets
BPR
Factorization Machines
Tensor Factorization (context)
NMF
SLIM