En esta clase
- Resumen Clase anterior
- Por qué otra versión de CF?
- Filtrado Colaborativo Basado Items (Sarwar et al. 2010)
- Referencias
Denis Parra
Profesor Asistente, DCC, PUC CHile
Recommender Systems aim to help a user or a group of users in a system
to select items from a crowded item or information space.
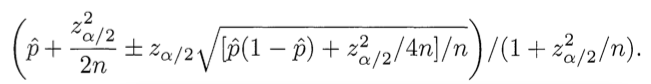
\[Similaridad(u,v) = w(u,v), v \in K\] \[\hat{p}_{u,i} = \bar{r}_u + \alpha \sum_{v \in N(u)}{w(u,v)(r_{v,i} - \bar{r}_v)}\]
Exactitud: Mientras más vecinos \(K\) consideramos (bajo cierto umbral), mejor debería ser mi clasificación (Lathia et al. 2008)
Escalabilidad: Pero mientras más usuarios \(n\) existen en el sistema, mayor es el costo de encontrar los K vecinos más cercanos, ya que K-NN es \(O(dnk)\). Considerando un sitio con millones de usuarios, calcular las recomendaciones usando este método \(memory-based\) se hace poco sustentable.
Model-based methods: Redes Bayesianas (ideales en casos en que las preferencias del usuario no cambian tan a menudo), Reducción de dimensionalidad (estado del arte, pero tiene algunos costos de implementación, especialmente en "tunear" los parámetros)
Clustering, aunque tienen como efecto producir recomendaciones "no tan personalizadas" y, disminuir la exactitud de las predicciones en algunos casos (Breese et al. 1998)
Graph-based methods: Horting, Random Walks, Spread of activation. Son menos precisos, pero contribuyen a dar mayor diversidad a las recomendaciones
Item-base recommendation: Revisar user-based (precisión + simpleza) y escalarlo :-)
| User-Based | Item-Based |
|---|---|
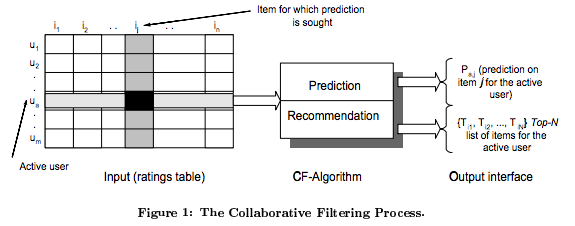 |
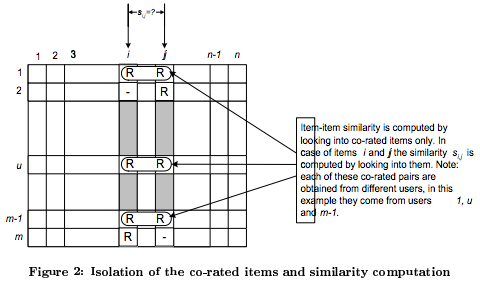 |
*Imágenes del articulo de Sarwar et al. 2010, Item-Based Collaborative Filtering Recommendation Algorithms
Cosine-Based Similarity \[sim(i,j) = cos(\vec{i},\vec{j}) = \frac{\vec{i}\cdot\vec{j}}{\|\vec{i}\|_2 \times \|\vec{j}\|_2}\]
Correlation-Based Similarity \[sim(i,j) = \frac{\sum_{u \in U}{(R_{u,i}-\bar{R}_i)(R_{u,j}-\bar{R}_j)}}{\sqrt{\sum_{u \in U}{(R_{u,i}-\bar{R}_i)^2}}\sqrt{\sum_{u \in U}{(R_{u,j}-\bar{R}_j)^2}}}\]
Adjusted Cosine Similarity \[sim(i,j) = \frac{\sum_{u \in U}{(R_{u,i}-\bar{R}_u)(R_{u,j}-\bar{R}_u)}}{\sqrt{\sum_{u \in U}{(R_{u,i}-\bar{R}_u)^2}}\sqrt{\sum_{u \in U}{(R_{u,j}-\bar{R}_u)^2}}}\]
1 - Jaccard distance (Das et al. 2007)
\[\hat{P}_{u,i} = \frac{\sum_{all\ similar\ items,\ N}{(sim(i,N) \cdot R_{u,N})}}{\sum_{all\ similar\ items,\ N}{sim(i,N)}}\]
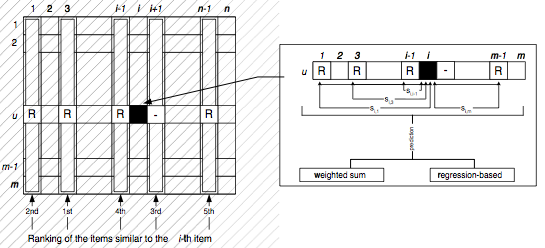
Si bien este método podría considerarse memory-based, los autores de Sarwar et al. lo consideran model-based, donde el parámetro principal del modelo es K (número de ítems similares a considerar)
Los autores usan MAE (Mean Absolute Error) para evaluar métodos.
Resultados importantes para considerar en el análisis:
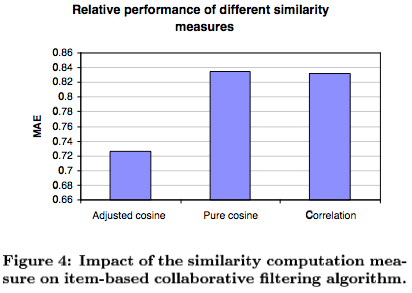
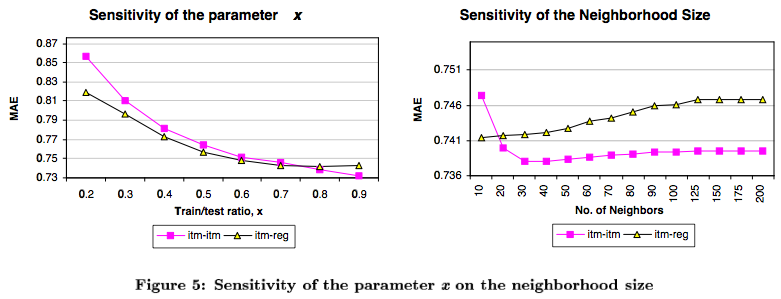
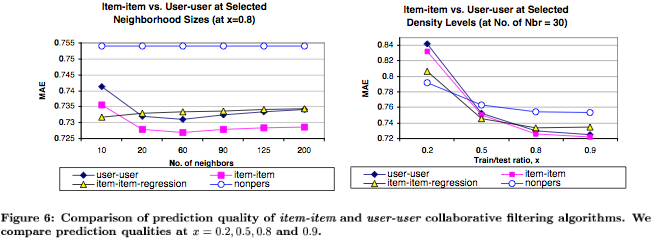
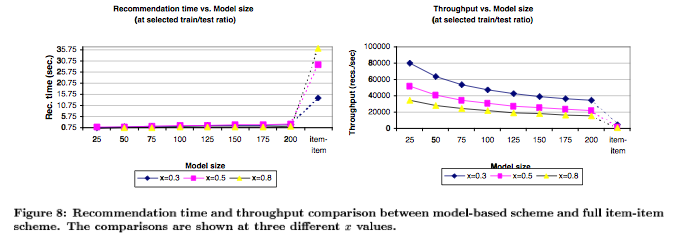
Leer Das et. al "Google News Personalization: Scalable Online Collaborative Filtering", que, para usando patrones de co-visita, incluye: